
How to Summarize Podcasts Using AI
If we don’t want to listen to the entire podcast episode, we can use AI technology to summarize the entire podcast audio, extract key points, and achieve a quick understanding of the podcast content.
So, if we want to summarize a podcast episode, we can complete it through the following steps.
Step 1: Obtain the Podcast’s RSS Address
Most podcast episodes provide their own RSS address for easy subscription and listening. Generally, you can find information about the RSS address in the podcast information provided by the podcaster.
If the podcast is also available on Apple Podcasts, another convenient way is to use the iTunes API to query podcast information, which will allow you to obtain the RSS address.
curl https://itunes.apple.com/search?term=<Podcast Name>&entity=podcast&attribute=titleTerm | jqStep 2: Parse the RSS and Obtain Episode Audio URLs
In this step, you can use command-line tools like curl to directly access the RSS address and then search for the episode you want to summarize in the returned results. Once you locate it, you can find the audio download URL.
If you are using the Go programming language, you can utilize the gofeed library to parse the RSS and retrieve various program information.
Step 3: Download Audio and Transcribe into Text
OpenAI’s open-source solution, Whisper, is a mature technology for converting audio to text. The open-source nature of Whisper is quite commendable.
Reminder: When using Whisper, it’s advisable to provide a simple prompt. Failing to provide a prompt may lead to some unusual issues, such as missing punctuation or inaccurate transcription of unfamiliar words.
This step is fundamental, and the quality of Whisper’s transcription will directly impact the quality of the subsequent summarization.
Step 4: Parse the Transcript Text and Split It
The transcript text generated by Whisper is usually quite extensive, especially for long podcast episodes. In this step, the text needs to be segmented into multiple sections to make it suitable for summarization by models like ChatGPT. This is necessary because, for well-known reasons, language models have context length limitations. Even with GPT-4, the context length is only 32k, which is far from sufficient for a transcript of a multi-hour podcast.
Regarding segmentation, you can use basic criteria like character/byte size, but this may not always be the best approach as it can split phrases or sentences. For podcasts, Whisper’s transcript results are often structured into statements generated at intervals of time. You can segment the text based on time intervals, such as every 3 minutes, to ensure complete sentences are preserved. If there are speaker tags, you can incorporate speaker detection during segmentation to group all speech by the same speaker into one segment, especially in multi-person conversations, to prevent one person’s speech from being split.
In summary, the addition of various strategies and algorithms aims to make the segmentation as content-appropriate as possible. This is an area worth continuous improvement.
Step 5: Use ChatGPT to Summarize Each Segment One by One.
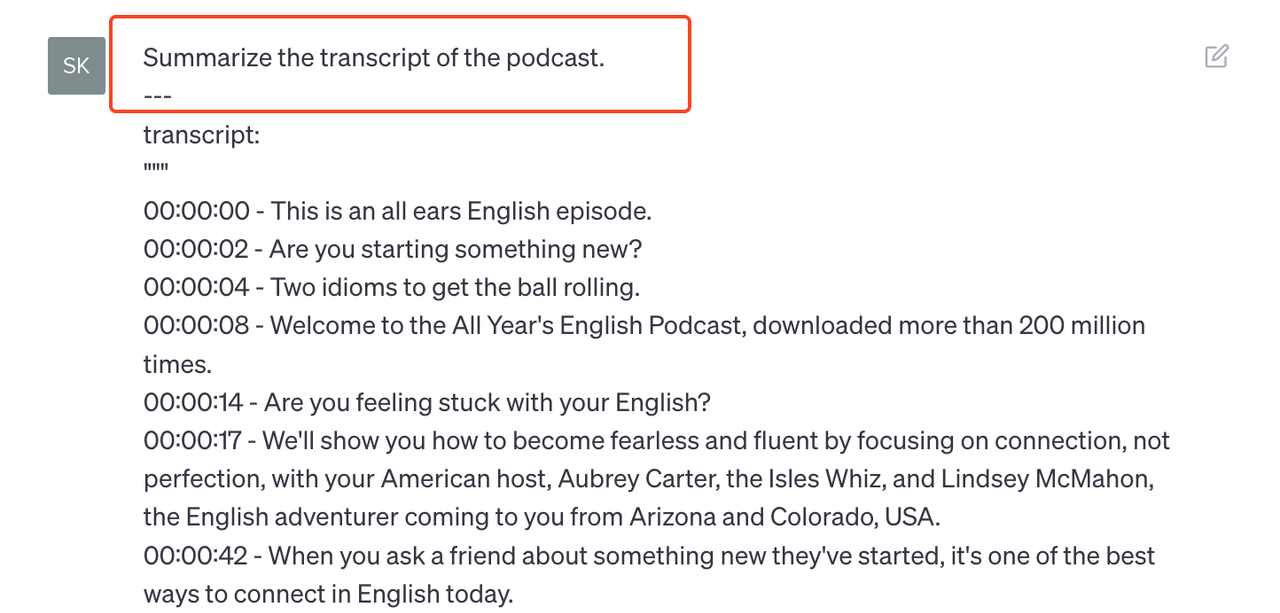
Step 6: Completion
Combine all the segments to create a chapter outlines and other content.
I find this process to be quite labor-intensive and challenging to consistently control the quality of each summary. However, using Podwise, podcast summarization can be accomplished in just two simple steps.
Step 1: Search for the Podcast Episode 🎙️
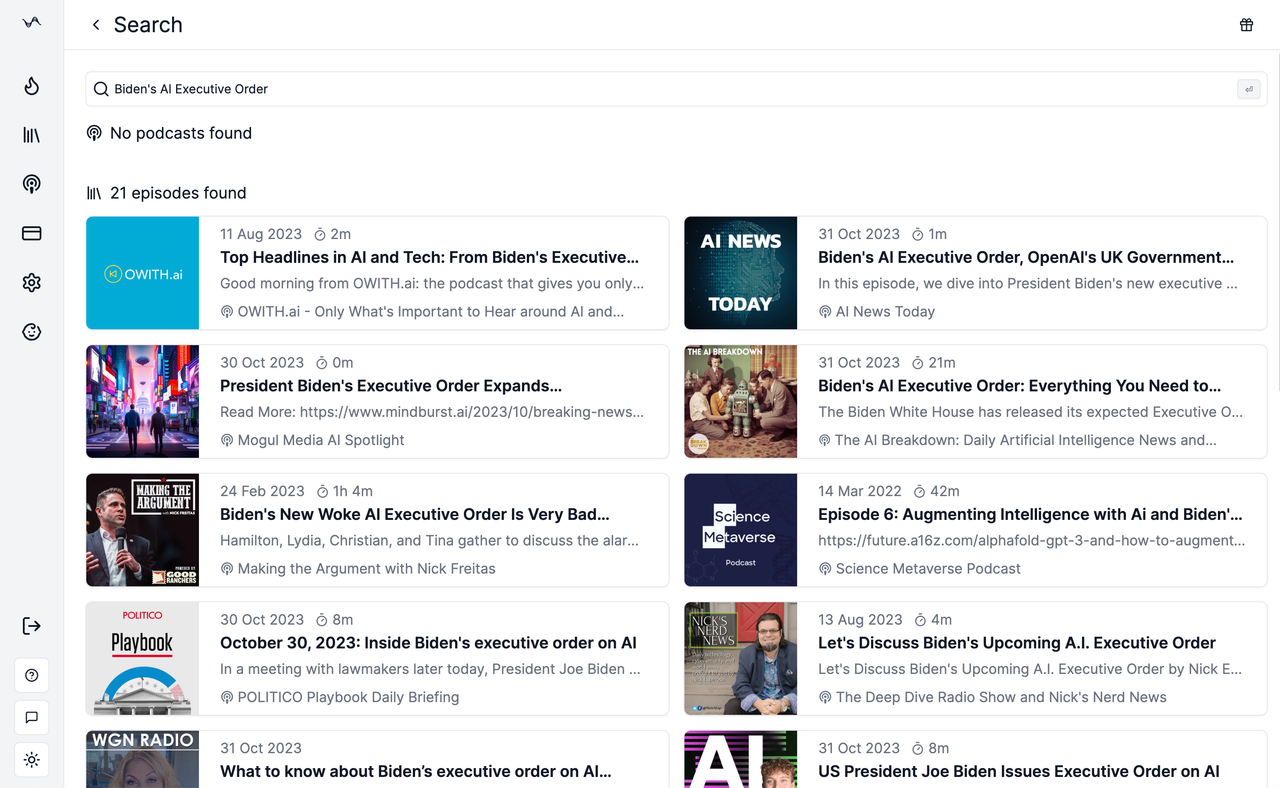
Step 2: Click the “Transcribe” Button and Wait for It to Complete 🚀
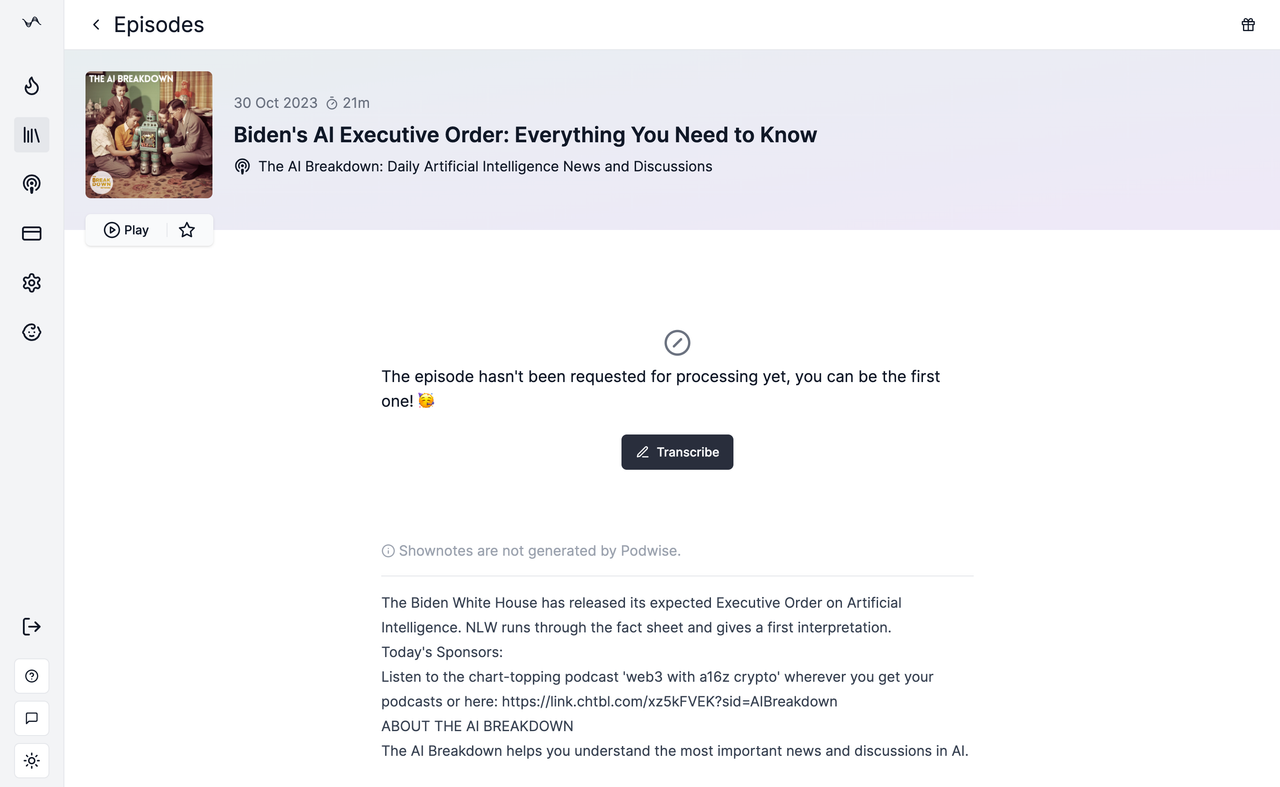
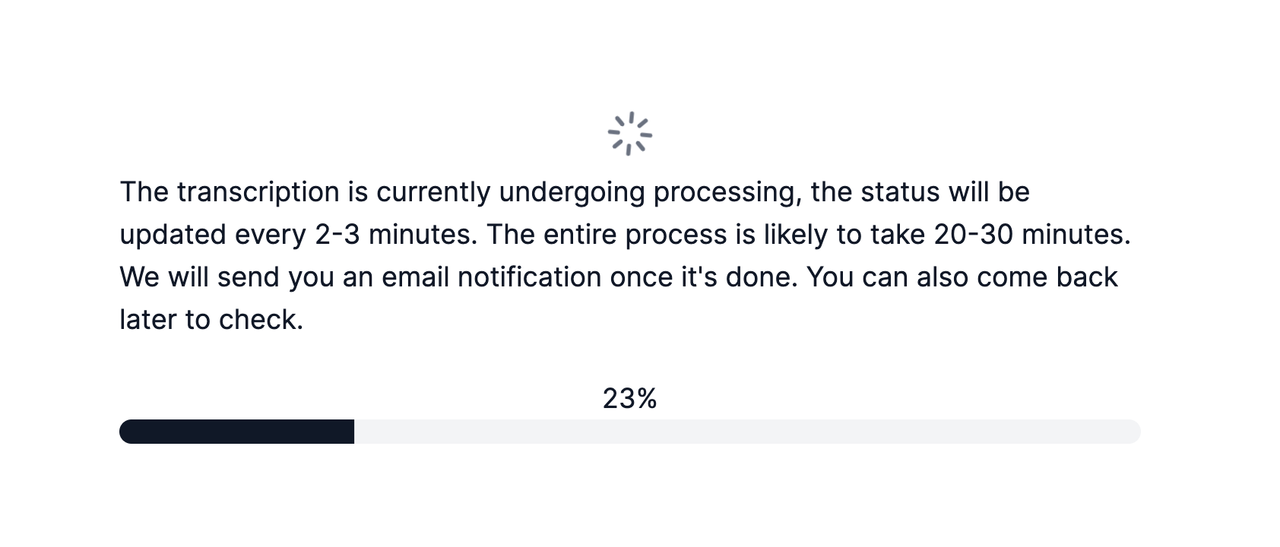
Step 3: Have a Cup of Coffee and Enjoy the Podcast ☕️
So convenient and cool 🎧