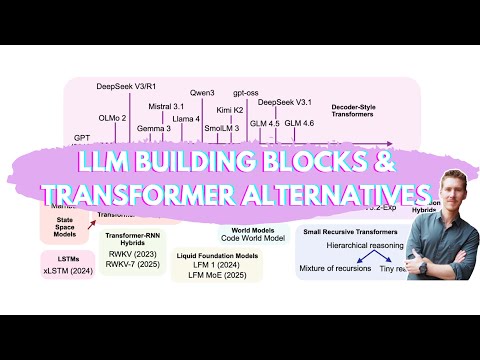
In this monologue podcast, Sebastian Raschka discusses the LLM (Large Language Model) landscape in 2025, focusing on major LLMs, emerging alternatives, and his thoughts on these alternatives. He begins with the transformer-based, state-of-the-art, open-weight models, mentioning DeepSeq and GLM 4.6. He then discusses grouped query attention, multi-head latent attention, and sliding window attention as tricks to lower inference requirements. He also touches on the mixture of experts. Furthermore, he explores alternatives to the main track LLMs, such as gated DeltaNet, sparse attention mechanisms, tiny reasoning models, code world models, text diffusion models, liquid foundation models, transformer RNN hybrids, and Mamba state-space models. He also mentions his upcoming book, "Build a Reasoning Model from Scratch."
Sign in to continue reading, translating and more.
Continue
