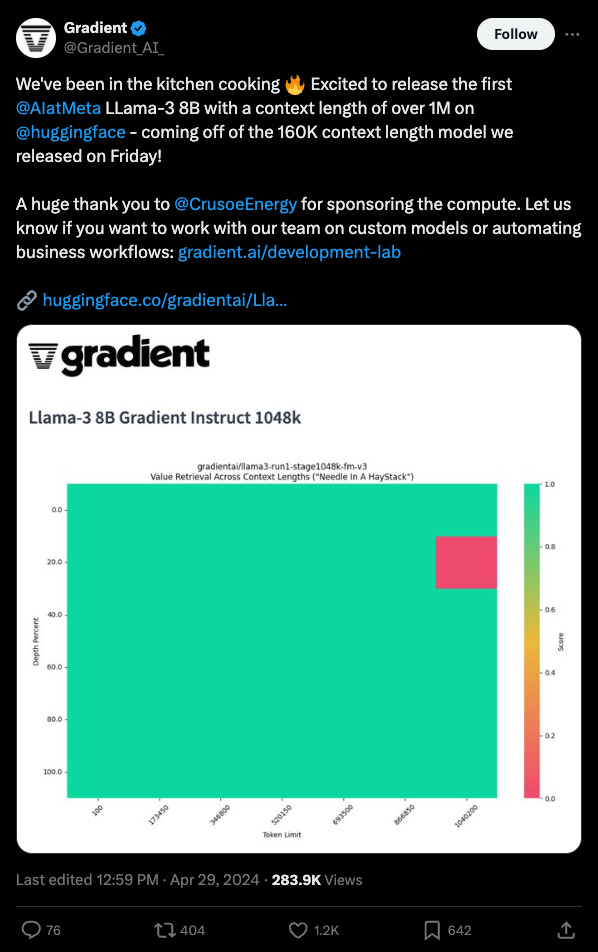
In this episode of the Latent Space Podcast, Mark Huang from Gradient shares insights into their efforts to expand the context window of large language models, particularly Llama 3. He explains their innovative approach, which employs a curriculum learning method utilizing datasets like SlimPajamas and UltraChat. The discussion highlights the challenges of scaling to millions of tokens, including the significance of positional encoding (RoPE) and the constraints of floating-point precision. They also explore various benchmarking techniques, such as Ruler and Zeroscrolls, and the application of LoRA adapters to enhance model capabilities. Looking ahead, the conversation delves into the future of long-context learning, emphasizing the shift towards multimodality and more sophisticated evaluations that go beyond simple "needle in a haystack" tasks. Huang underscores the critical role of data quality, synthetic data generation, and community collaboration in driving progress in the field.
Sign in to continue reading, translating and more.
Continue