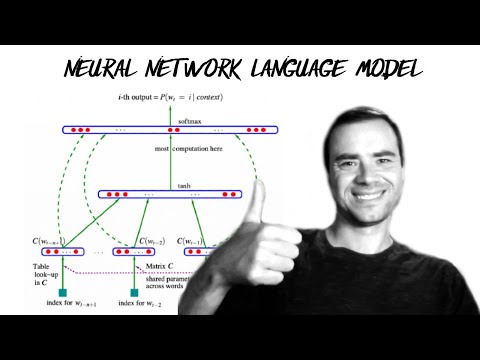
This episode explores the implementation of a multilayer perceptron model for character-level language modeling, building upon a previous bigram model. Against the backdrop of the limitations of bigram models in handling larger contexts, the speaker introduces a multilayer perceptron approach inspired by the Ben-Juattel 2003 paper. More significantly, the discussion delves into the practical implementation using PyTorch, focusing on embedding lookup tables, hidden layer construction, and efficient concatenation techniques. For instance, the speaker demonstrates the use of `torch.view` for efficient tensor manipulation, contrasting it with less efficient concatenation methods. The training process is detailed, including mini-batch optimization, learning rate determination, and learning rate decay. The episode concludes with insights into overfitting, the importance of train/dev/test splits, and hyperparameter tuning, highlighting the iterative nature of model development and optimization. What this means for future development is the potential for more sophisticated language models with improved performance through careful hyperparameter tuning and optimization techniques.
Sign in to continue reading, translating and more.
Continue