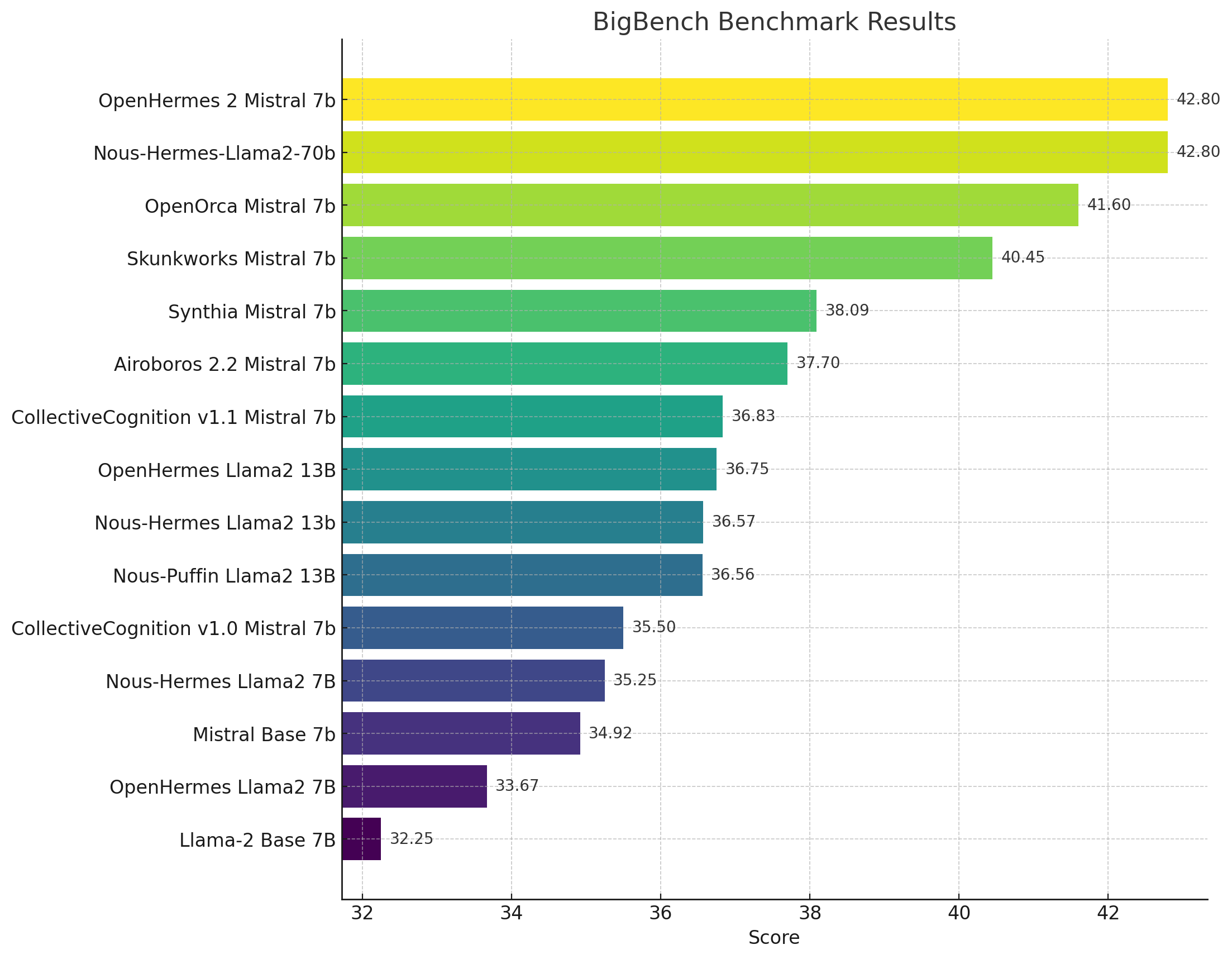
This podcast episode discusses various topics related to the open source AI community. It covers presentations made by companies and industry experts, the personal journey of Axolotl in fine-tuning language models, the concept of fine-tuning and its importance, challenges in evaluating AI models, the significance of open source models and licensing considerations, OpenAI's legal claims, technical aspects of parameter efficient fine-tuning techniques, and the advancements in flash attention and the Mamba model. The episode provides insights into the latest advancements, challenges, and considerations in the AI community. Takeaways • The open source AI meetup showcased presentations by companies like Alignment Labs and News Research, highlighting advancements and products. • The personal journey of Axolotl in fine-tuning language models faced challenges such as merging data sets and limitations in existing ecosystem tools. • Fine-tuning involves training open-source models with custom datasets to enhance their performance for specific use cases. • Data contamination is a challenge in evaluating AI models, and developers need to acknowledge and rectify such issues. • Open source models, such as GPT-4 by Technium, provide possibilities and advancements in the AI community. • Orca, a model focusing on chain of thought reasoning, and its open reproduction were discussed, highlighting the role of the open-source community. • Fine-tuning techniques like Lora and Q-Lora involve freezing base model layers and adding additional layers for training. • Evaluating and selecting AI models require considering benchmarks, beyond the limitations of benchmark-based evaluations. • Usage and licensing of open-source AI models require understanding legal complexities, restrictions, and compliance. • OpenAI's claims and the training of models raise legal and ethical questions, while parameter efficient fine-tuning techniques offer efficient training methods. • The Parameter Efficient Fine-Tuning (PFT) module integrates with Huggy Face Transformers for effective fine-tuning. • Neftune and accelerator communities provide valuable insights, feedback, and experiences for improving user experiences. • StackLlama and Multipack are techniques optimizing training data by appending multiple rows and incorporating lower block triangular attention mask. • Multi-pack feature significantly improves performance and reduces costs in data processing tasks. • Flash attention and the Mamba model offer improved inference speed and memory requirements for larger models and longer context lengths.
Sign in to continue reading, translating and more.
Continue